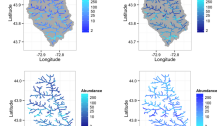
Mapping Abundance in Streams in R
I haven’t worked with raster or spatial polygon data in R much before, but I want to create maps to show the results of a spatiotemporal model. Specifically, I want to depict the changes in abundance of fish in a stream network over time and space. I decided to play around with various packages for…
